






Trying Amazon API Gateway, Lambda and DynamoDb
At the beginning of June 2016, I visited a JavaDay conference in Lviv, where I listen to a talk about serverless architecture. Today I’d like to try serverless.
According to Martin Fowler, serverless is an architecture, which uses third party services or a custom code on ephemeral containers, best known as Amazon Lambda. So, I understand it as an idea to run your backend code on demand: there won’t be any real servers like EC2, Amazon infrastructure will start a container, which will run your Lambda function. Consider reading this article for explanations. I’d like to try this infrastructure.
I decided to use Amazon API Gateway and Amazon Lambda for analyzing GitHub repositories: after each push to the repository I will examine all .md files and store them to Amazon Dynamo Database. More generally, I’ll create a backend part for a self-written blogging platform. Who knows, maybe I will write a frontend part soon.
General plan
The approach isn’t clear enough, so let’s clarify what do we need:
- We want to save articles on GitHub
- We need to have an API for our blog
- Since we need to have a good latency for API, reading articles from GitHub is not an option for us. So, we need some storage. For this post, I choose Amazon DynamoDB.
- We need to have a backend part. I’ll be using Amazon Lambda.
How it’s going to work:
- GitHub will send a WebHook to Amazon Lambda through API Gateway. WebHook will contain information about all new, updated or removed articles, so will handle each type of event accordingly.
- Amazon Lambda will receive an event, and process all affected items. All the elements will be inserted, updated or removed from Amazon DynamoDB.
- There’ll be a second Lambda function, which will give paginated information about articles.
Following diagram explains how blog posts will be handled by our system.

Create IAM role
Before you start, you need to create some role for lambda. I created a lambda-demo role with following policies:
- AWSLambdaFullAccess
- AmazonDynamoDBFullAccess
I believe, there should be more restricted policies, but for demo purpose, I decided not think about that.
Here’s how it should look
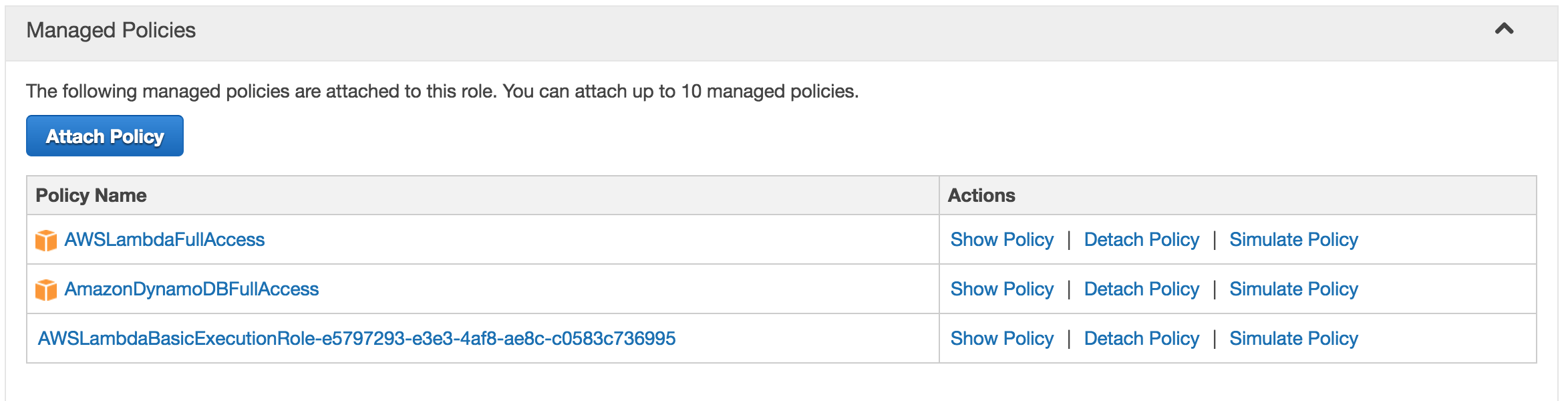
This two policies will us a green light on running Amazon Lambda and working with DynamoDB.
Create Amazon DynamoDB table
Go to Amazon DynamoDB dashboard page and create a table with posts table name and title key. We don’t need to create more columns, this is just an example.
Creating Lambda functions
According to documentation, to run lambda, you need to upload a .zip file with Java classes. You’ll need to provide a full reference path, together with packages prefix.
I created a separate repository for you so don’t need to copy every piece of code from blog - github.com/ivanursul/amazon-lambda
There are only two lambda functions:
- ProcessRequestHandler, which process GitHub WebHook and saves/updates/removes articles from DynamoDB
- ArticlesRequestHandler, which exposes information about articles.
Clone this project to your local machine, build it with
gradle clean build
go to build/distributions/ and make sure archive amazon-lambda.zip is present there.
Next, go to Lambda Management Console and perform following steps:
- Press
Create a Lambda function. - Choose
Blank function. - Next
- Fill in following data
- Name -> ProcessRequestHandler
- Runtime -> Java 8
- Code entry type -> Upload a zip file
- Handler -> org.ivanursul.blog.ProcessRequestHandler
- Role -> Choose an existing role
- Existing role -> lambda-demo
Repeat the same steps with the second function, ArticlesRequestHandler.
Creating API Gateway
Having just a Lambda function is not enough for using it with GitHub. We need to expose it to HTTP protocol. If we are using Amazon products here, then it’s obvious to try Amazon API Gateway
We need to expose two lambda functions - ProcessRequestHandler and ArticlesRequestHandler.
You need to perform several steps for connecting lambda with api gateway:
- Enter API Gateway Console
- Press Create API
- Choose Import from Swagger
- Paste content from amazon-lambda-api-gateway.yaml
- Additionally, you need to configure Lambda integration
Here’s how ArticlesRequestHandler API Gateway should look like:

Next, add Body Mappings Template: application/json with empty string content.
Do the same with ProcessRequestHandler, but add another application/json mappings template:
{
"body" : $input.json('$')
}
Save, and Deploy your API.
Configuring WebHook
After you deploy API Gateway, you need to specify a link for ProcessRequestHandler gateway for your WebHook.
Go to your blogging repository on the Settings page, then on WebHook section and put the link.
In my case, it looks like this
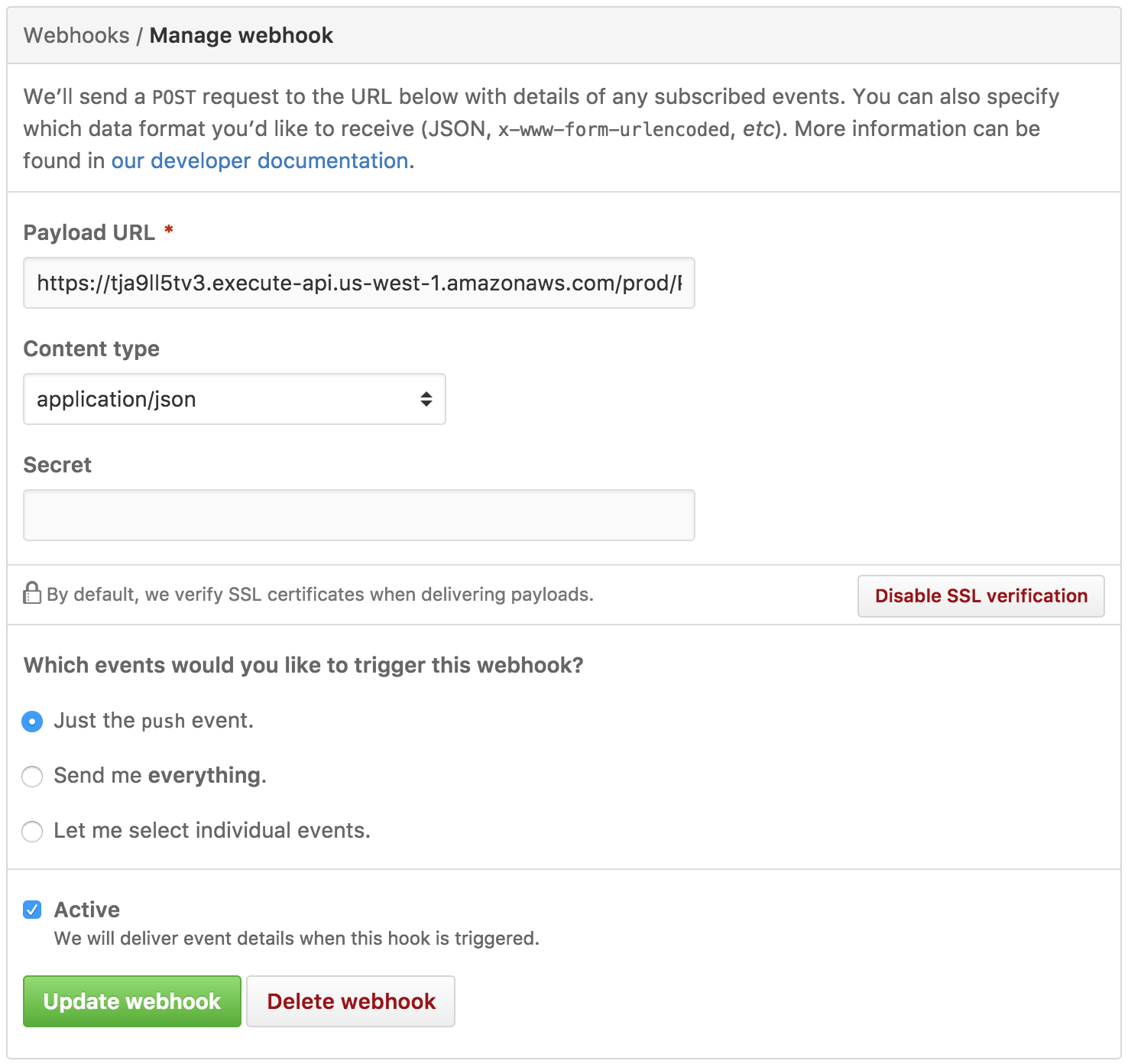
Link example: https://tja9ll5tv3.execute-api.us-west-1.amazonaws.com/prod/ProcessRequestHandler You should have something similar.
If you fail with text instuction, you can watch video:
<a href=”#conclusions name=”conclusions”></a> Conclusions
What I’ve learned from Amazon Lambda?
- There’s an instrument, which allows you to write and deploy some logic within minutes. You just need to write a single function, pack it inside a zip file, and upload to Amazon. Great, doesn’t it?
- If you have small traffic, it will cost you few cents per month.
- It takes a time to deploy your single line function to Amazon container and to run it, so don’t put large libraries inside.
- If you start to use some of Amazon products, it’s extremely hard to use just one tool. Without fail, you will need to use other products, so be ready to learn them. I found it harder to use MongoDB, than DynamoDB, in this case. The problem is that we are accustomed to using servers in our backend applications and it’s okay to start an application within 3-5 seconds. Here, inside Lambda, we need to calculate every millisecond.
- Don’t hesitate on removing old Lambda’s, which you don’t use.
PS - This blog post is now a part of Deployment Using Containers WIKI